
大模型微调的技术深度探讨,含金量究竟有多大?
随着人工智能技术的飞速发展,深度学习已成为众多领域的核心驱动力,大模型微调(Fine-tuning)作为深度学习中的一种常见技术,广泛应用于图像识别、自然语言处理等领域,关于大模型微调到底是否具有技术含量,以及技术含量有多大,业界存在着不同的看法,本文旨在深入探讨大模型微调的技术内涵及其重要性。

大模型微调概述
大模型微调是一种将预训练模型应用于特定任务的方法,在深度学习领域,预训练模型通常是在大量无标签或标注数据上训练得到的,已经学习到了通用的特征表示,当面临特定任务时,我们可以通过微调预训练模型的参数,使其适应新任务的数据分布和特征,大模型微调的步骤通常包括:加载预训练模型、冻结部分参数、修改输出层以适应新任务、训练模型以及评估模型性能。
大模型微调的技术含量
技术复杂性
大模型微调虽然看似简单,但背后涉及的技术复杂性不容忽视,需要深入理解预训练模型的内部结构和原理,以便选择合适的预训练模型并对其进行微调,针对特定任务,需要对预训练模型进行精细化调整,包括参数优化、网络结构修改等,还需要掌握数据预处理、超参数调整等技能,以确保微调后的模型能够在新任务上取得良好性能。
技术深度
大模型微调的技术深度主要体现在对深度学习理论、算法和计算资源的高要求上,为了进行有效的微调,需要对深度学习算法有深入的理解,包括梯度下降、优化器、损失函数等,由于大模型通常需要大量的计算资源,因此还需要掌握分布式计算、GPU/TPU等高性能计算技术。
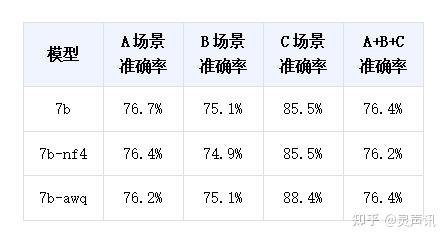
技术创新与应用拓展
大模型微调在技术创新和应用拓展方面具有重要意义,随着深度学习技术的发展,越来越多的预训练模型被提出,如BERT、GPT等,这些模型的提出为大模型微调提供了丰富的资源和技术支持,通过微调这些预训练模型,我们可以快速适应各种新任务,提高模型的性能,大模型微调还可以应用于迁移学习、多任务学习等领域,为深度学习的应用拓展提供了更多可能性。
大模型微调的挑战与未来趋势
尽管大模型微调具有诸多优点,但也面临着一些挑战,预训练模型的规模庞大,需要大量的计算资源和存储空间,微调过程需要针对特定任务进行精细化调整,这需要对领域知识和技术有深入的理解。
展望未来,我们期待在大模型微调方面取得更多的突破,更高效的数据处理方法、更优化的超参数调整方法等,大模型微调作为一种常见的深度学习技术,其技术含量不容忽视,随着深度学习技术的不断发展,我们期待大模型微调在更多领域得到应用,并推动人工智能技术的进步,大模型微调也将继续引领深度学习领域的发展,为我们带来更多创新和突破。
转载请注明来自星韵禾,本文标题:《大模型微调的技术深度探讨,含金量究竟有多大?》






 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号